
Generative AI just got smarter: Retrieval‑Augmented Generation (RAG) is changing the game by fusing vast knowledge bases with creative output, unlocking systems that don’t just generate but understand. However, this advancement brings forth a new array of challenges, especially regarding security, reliability, and the protection of AI-generated content. In this detailed guide, we will examine the security issues associated with RAG applications and discuss practical methods for implementing safeguards using open-source tools and frameworks. Nvidia is now developing secure and reliable medical apps with RAG and Nvidia NeMo Guardrails, which is their own RAG guardrail. Here’s a deep dive on guardrails for RAG. They have also created a voice agent with RAG and safety guardrails.
Understanding the Security Challenges in RAG Applications
RAG models consist of two essential elements: retrieval (the process of extracting relevant information from external sources) and generation (the creation of natural language responses). While this combination allows for more contextually accurate and dynamic outputs, it also introduces several distinct security challenges:
- ● Data Privacy and Leakage: The use of external databases by RAG systems can unintentionally expose or retrieve sensitive information, resulting in privacy concerns.
- ● Hallucination and Misinformation: Generative models have the potential to produce plausible yet incorrect information, and when paired with external data, they may heighten the risks of disseminating misinformation.
- ● Inconsistent Output Quality: The retrieval process may source outdated or irrelevant data, which can diminish the reliability of the output.
- ● Bias and Toxicity: RAG models might draw from biased or toxic sources, leading to harmful outputs that mirror the biases present in the data they access.
- ● Vulnerabilities in External Data Sources: By depending on external data, RAG systems may become susceptible to poisoned datasets or adversarial attacks aimed at manipulating their outputs.
What Causes AI Hallucinations?
AI hallucination refers to a phenomenon in which a large language model (LLM), commonly found in generative AI chatbots or computer vision tools, identifies patterns or objects that do not exist or are not detectable by human observers, resulting in outputs that may be nonsensical or completely incorrect. AI hallucinations happen when artificial intelligence systems produce inaccurate or deceptive information, frequently as a result of issues such as overfitting, biases in training data, and the fundamental architecture of large language models that emphasize conjecture rather than recognizing uncertainty.
Types of Guardrails to Secure RAG Models
Guardrails help address specific security challenges, here are some types of guardrails in RAG and how they help safeguard organizations and systems.
- ● Input Safeguards: These are aimed at securing the model's inputs, ensuring that the data sourced from external origins is verified, accurate, and devoid of harmful content.
- ● Output Safeguards: These guarantee that the produced content is verified for accuracy, free from toxicity, and adheres to ethical guidelines.
- ● Protection Against Adversarial Threats: Safeguards that identify and thwart adversarial attacks, which seek to manipulate or compromise the system by taking advantage of weaknesses in data retrieval or generation.
- ● Measures for Data Privacy: Safeguards intended to avert the leakage of sensitive information during retrieval, ensuring that private or confidential data is not unintentionally revealed.
- ● Guardrails for Bias Reduction: These aim to lessen the chances of biased outputs by regulating the sources from which the RAG model gathers information or by post-processing the outputs of the model.
Importance of AI Guardrails for RAG
AI guardrails in Retrieval-Augmented Generation (RAG) systems serve as safety mechanisms aimed at ensuring the system functions properly and generates dependable outputs. These guardrails assist in avoiding problems like harmful content, data leaks, and compliance breaches by functioning as filters, validators, and monitors within the RAG pipeline.
Without RAG Guardrails, AI guardrails in Retrieval-Augmented Generation (RAG) systems are safety mechanisms designed to ensure that the system operates correctly and produces reliable outputs. They help prevent issues such as harmful content, data exposure, and compliance violations by acting as filters, validators, and monitors throughout the RAG pipeline. AI models and chatbots are susceptible to manipulation. Through methods like jailbreaks or prompt injection exploits, a large language model (LLM) can inadvertently reveal personally identifiable information (PII), aid in the dissemination of misinformation, or leak sensitive data. If these vulnerabilities are not addressed, they can lead to phishing scams and the proliferation of harmful content on a large scale, jeopardizing system performance and resulting in expensive security incidents.
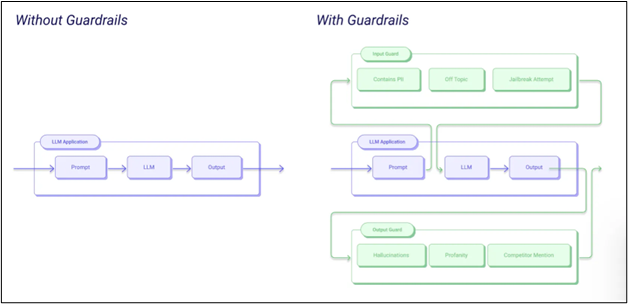
The implementation of AI guardrails is essential to convert experimentation into ethical and sustainable innovation. These guardrails strike a balance between speed and safety, ensuring that the use of AI is responsible and in accordance with regulatory standards, stakeholder expectations, and long-term business objectives. Recently, Bloomberg has implemented RAG guardrails to mitigate risky RAGs in finance.
3 Ways How AI Guardrails Practice Across Enterprises
Juggling between safety, policy, dependable workflows and ethics have been a pressing concern in today’s world. Well, here’s how AI guardrails help overcome these challenges and spearhead the way how they reshape and transform industries.
Enhancing Cybersecurity
AI guardrails play a crucial role in defending against an expanding array of threats. Vulnerability management teams utilize these tools to identify and address risks, including coordinated misinformation campaigns.
AI security measures are integrated into workflows to avert data privacy breaches and unauthorized access to sensitive datasets. By aligning with comprehensive cybersecurity strategies such as threat detection and response (TDR) and zero trust principles, threat guardrails can minimize the attack surface generated by AI systems and safeguard enterprise trust.
Establishing Dependable Workflows
Organizations also depend on guardrails to guarantee the smooth operation of AI workflows. Intelligent automation and agentic workflows rely on real-time AI agents capable of making swift and secure decisions. AI guardrails serve as a vital balancing mechanism to facilitate this process.
For instance, a healthcare chatbot can provide timely patient information without compromising sensitive data, while a finance application can automate fraud detection without generating false positives. This illustrates how guardrails function at scale: not merely as isolated checks, but as integrated components. By incorporating guardrails into workflows, organizations can harness the benefits of AI while ensuring compliance and maintaining trust.
Protecting Against Harmful Content
Guardrails can be directly integrated into model pipelines to filter out harmful or sensitive content. HAP filtering employs a classification model to identify and eliminate hate speech, abusive language, and profanity from the input and output text of a large language model (LLM). This process typically involves classifiers that examine both inputs and outputs, sentence by sentence, to identify risky language or sensitive information before it reaches the end user. If any flagged content is detected, the system either blocks it or replaces it with a notice, thereby preventing unsafe text from being disseminated. Here are a few types of filters.
- ● Harmful language filters: Identify and prevent hate speech, abusive language, or profanity. Sensitivity levels can be adjusted to find a balance between safety and the likelihood of false positives.
- ● PII filters: Detect personally identifiable information, including phone numbers, emails, or account numbers, and ensure it remains confidential.
- ● Advanced safety filters: Employ more sophisticated models to identify problems such as jailbreak attempts, bias, hallucinated responses, or violent and unethical content.
These filters can be implemented in various ways—via visual tools, APIs, or software development kits (SDKs)—and sensitivity levels can be modified to align with an organization’s risk tolerance. Lower sensitivity levels may capture more potential issues but could also flag safe content excessively, while higher levels may reduce unnecessary alerts but risk overlooking some threats.
With increasing emergence of ethical and reliability concerns in LLMs and gen AI powered outputs, companies are on the lookout for RAG engineers to establish concrete guardrails to overcome these challenges. At Eduinx, a leading edtech institute in India, we will guide you in implementing RAG in real-time. Our non-academic mentors are here to help you understand concepts through virtual classrooms. We also provide placement assistance and help you land your dream job as an RAG engineer. Get in touch with us to know more about our PG diploma course in generative AI.



