
The RAG revolution has a new engine: Mixture-of-Experts (MoE) is officially rewriting the playbook for how LLMs retrieve and process information. MoE is now being used to power next gen in dic LLMs They have also expanded from LLMs to speech recognition and are transforming the financial services landscape.
A mixture of experts (MoE) is an architectural framework for neural networks that divides the computation of a layer or operation (like linear layers, MLPs, or attention projection) into several "expert" subnetworks. Each of these subnetworks carries out its own computation independently, and the results are merged to produce the final output of the MoE layer. MoE architectures can be classified as either dense, where every expert is utilized for each input, or sparse, where only a subset of experts is employed for each input.
In scenarios involving large prompts and batches where computation becomes the limiting factor, the MoE architecture can be employed to reduce the latency of serving the first token. The significance of reducing latency is heightened in use cases such as retrieval-augmented generation (RAG) and autonomous agents, which may necessitate multiple calls to the model, thereby amplifying the impact of single-call latency.
Advantages of MoE
Mixture of Experts (MoE) models contribute to cost reduction by enhancing flop efficiency relative to weight. This implies that within frameworks that impose fixed time or computational cost limits, a greater number of tokens can be processed, allowing for additional training of the model. Since models with a higher number of parameters require more samples to achieve full convergence, it follows that MoE models can be trained more effectively than dense models when operating within a fixed budget.
In scenarios involving large prompts and batches where computation becomes the limiting factor, the MoE architecture can be employed to reduce the latency of serving the first token. The significance of latency reductions is heightened in use cases such as retrieval-augmented generation (RAG) and autonomous agents, which may necessitate multiple calls to the model, thereby amplifying the latency experienced in single calls.
How does an MoE Architecture Work?
Two primary elements are essential to MoE models. The first is the "expert" subnetworks that make up the mixture, utilized in both dense and sparse MoE. The second is the routing algorithm employed by sparse models to decide which experts handle which tokens. In certain formulations for both dense and sparse MoE, a weighting mechanism may be incorporated to calculate a weighted average of the outputs from the experts.
The MoE approach is implemented in Multi-Layer Perceptrons (MLPs) within transformer blocks. Here, the MLP in the transformer block is typically substituted with a collection of expert MLP subnetworks, whose outputs are aggregated to generate the MLP MoE result through averaging or summation. Here’s a brief on how MoE works.
- ● Expert Networks: Usually consisting of only a few feed-forward layers, each expert is essentially a smaller neural network. These professionals may specialize in a variety of fields; one may become exceptionally skilled at handling code, another at creative writing, and still another at mathematical reasoning.
- ● Gating Network: The "brain" that determines which experts to activate for each input token is the gating network (router). After examining the input, the gating network generates a probability distribution across all available experts.
- ● Sparse Activation: Only the experts who have been chosen are activated and contribute to the final product.
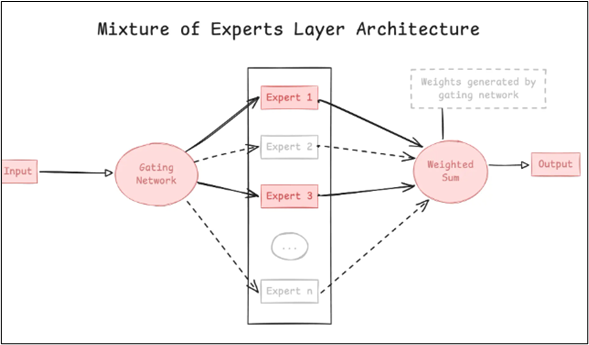
MoE models are more difficult to train than dense models because you have to make sure that every expert is used and specialized appropriately. In order to avoid the situation where all inputs are routed to a small number of "favorite" experts, leaving others unused, the gating network must learn how to make wise routing decisions.
MoE Ensures A Scalable LLM Architecture
A key element of MoE is the gating network, which functions as a traffic manager, skillfully directing inputs to the most appropriate expert(s) for processing. This adaptive selection of experts not only boosts efficiency by minimizing computational overhead but also improves model performance by enabling each expert to concentrate on its specific area of expertise.
MoE models are fundamentally sparse since only a fraction of experts is activated for each input. This sparsity results in considerable computational savings, as the model does not have to calculate the outputs of all experts for every input. Moreover, MoE architectures are exceptionally scalable; by increasing the number of experts, the model's capacity can be enhanced without a corresponding rise in computational costs. This characteristic makes MoE models especially well-suited for large-scale tasks.
The use of MoE in open-source LLMs presents numerous significant benefits. To begin with, it allows for the development of more advanced and capable models without the excessive expenses linked to training and implementing large, single-model frameworks. Additionally, MoE supports the creation of more focused and efficient LLMs, customized for particular tasks and fields. This targeted approach can result in considerable enhancements in performance, precision, and efficiency across various applications, including natural language translation, code generation, and personalized education and healthcare.
MoE in Implementing Scalable RAG
The Mixture-of-Experts (MoE) framework enhances scalable Retrieval-Augmented Generation (RAG) by utilizing a sparse architecture that activates only the relevant "expert" sub-networks for each query. This approach reduces computational costs while increasing the number of parameters. It enhances RAG by directing queries to specialized experts.
- ● MoE allows large language models (LLMs) to possess trillions of parameters while only activating a fraction of them, which decreases computational overhead and latency in comparison to dense models.
- ● MoE can leverage specialized experts for various aspects of RAG, such as domain-specific knowledge, leading to improved precision and minimized noise.
- ● MoE models implement a gating mechanism to selectively access external knowledge sources (RAG) based on the specific needs of the query, rather than conducting a search through the entire index each time.
- ● Techniques like Mixture of Document Experts (MODE) organize documents into clusters, enabling queries to be directed to particular document experts instead of searching through a single, large, inefficient vector database. By optimizing the routing of experts.
- ● MoE reduces bottlenecks, facilitating scalable model deployment in production without the need for proportionate and excessive increases in computational resources.
Future of MoE in LLMs
The Mixture of Experts (MoE) architecture provides a robust and effective method for enhancing model capacity, making it particularly suitable for extensive machine learning applications. Although MoE models present certain challenges, including training complexity and resource demands, their advantages in efficiency, scalability, and specialization render them a compelling choice for numerous applications.
Incorporating MoE architecture into open-source large language models (LLMs) marks a significant advancement in the development of artificial intelligence. By merging the strengths of specialization with the advantages of open-source collaboration, MoE opens up new avenues for developing more efficient, powerful, and accessible AI models that have the potential to transform the present industry.
Now that you have understood the core of how MoE in LLMs can be used in RAG, you need to know how to deploy them in real-time. Eduinx, a leading edtech institute in India, will guide you through a hands-on practical approach that helps you understand complex concepts in a simple way. Our expert mentors have over a decade of experience in gen AI and RAG applications. Get in touch with us to know more about our post graduate diploma course.



